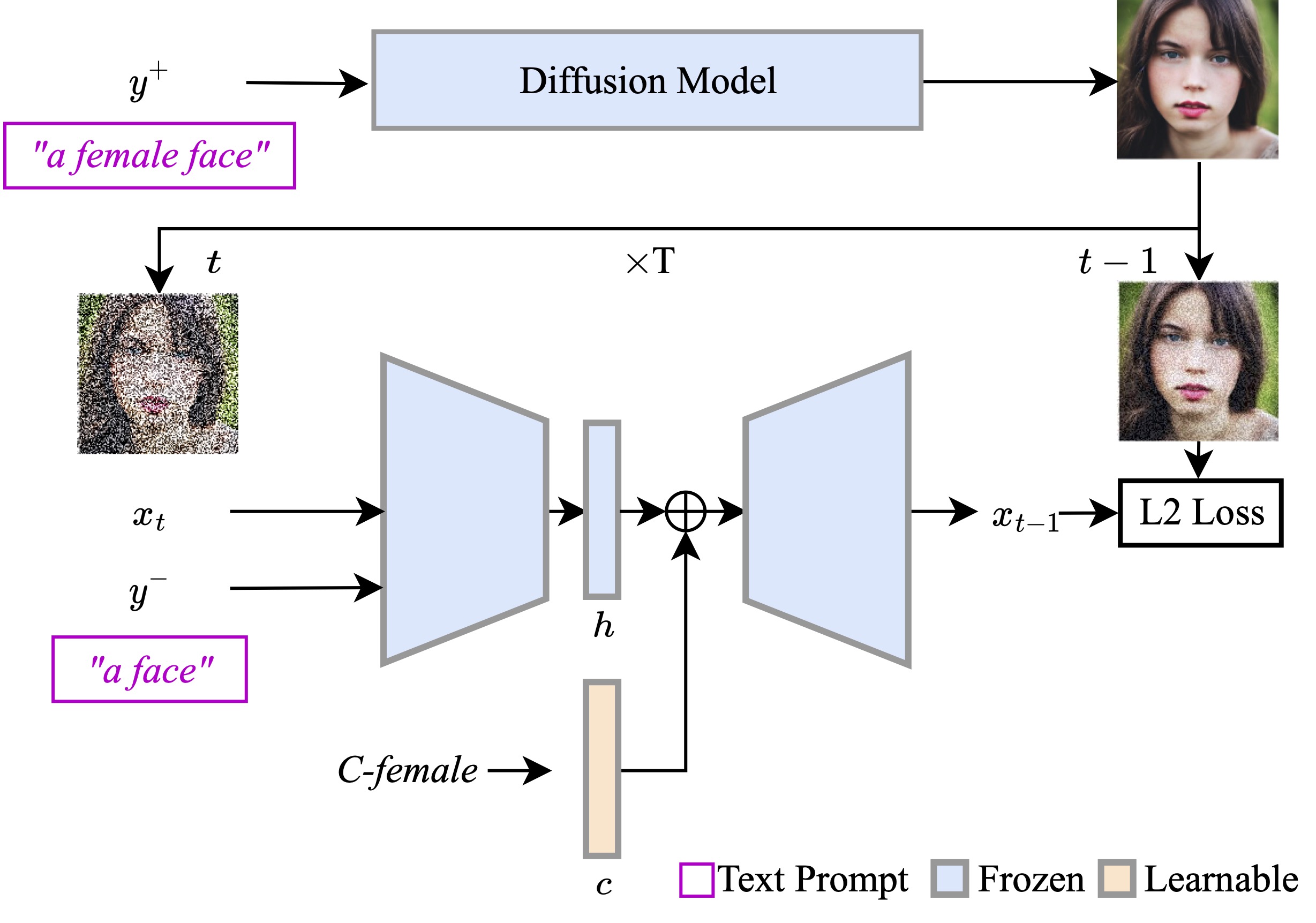
Diffusion-based models have gained significant popularity for text-to-image generation due to their exceptional image-generation capabilities. A risk with these models is the potential generation of inappropriate content, such as biased or harmful images. However, the underlying reasons for generating such undesired content from the perspective of the diffusion model's internal representation remain unclear. Previous work interprets vectors in an interpretable latent space of diffusion models as semantic concepts. However, existing approaches cannot discover directions for arbitrary concepts, such as those related to inappropriate concepts. In this work, we propose a novel self-supervised approach to find interpretable latent directions for a given concept. With the discovered vectors, we further propose a simple approach to mitigate inappropriate generation. Extensive experiments have been conducted to verify the effectiveness of our mitigation approach, namely, for fair generation, safe generation, and responsible text-enhancing generation.
@InProceedings{li2024self,
author = {Li, Hang and Shen, Chengzhi and Torr, Philip and Tresp, Volker and Gu, Jindong},
title = {Self-discovering interpretable diffusion latent directions for responsible text-to-image generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
}